How Do Actor-Critic Methods Utilize Reinforcement Learning Principles?
Actor-critic methods are a class of reinforcement learning algorithms that combine the advantages of both actor and critic networks to learn optimal policies for complex decision-making tasks. They have gained significant attention in recent years due to their effectiveness in various domains, including robotics, game playing, and natural language processing.

Reinforcement Learning Principles
Reinforcement learning is a type of machine learning that enables agents to learn optimal behavior through interactions with their environment. The key principles of reinforcement learning include:
- Environment: The agent interacts with an environment, which can be real or simulated, to gather information and make decisions.
- Actions: The agent can take various actions to influence the environment.
- Rewards: The environment provides rewards or penalties to the agent based on its actions.
- Policy: The agent's policy defines the mapping from states to actions.
- Value Function: The value function estimates the long-term rewards that the agent can expect from a given state.
Actor-Critic Methods
Actor-critic methods combine two neural networks: an actor network and a critic network. The actor network is responsible for selecting actions, while the critic network evaluates the value of those actions.
- Actor Network: The actor network takes the current state as input and outputs a probability distribution over possible actions. The agent selects an action based on this distribution.
- Critic Network: The critic network takes the current state and the selected action as input and outputs an estimate of the value of that action. This value estimate is used to update the actor network.
Training Actor-Critic Methods
Actor-critic methods are trained using a policy gradient algorithm. The goal of the training process is to maximize the expected cumulative reward that the agent can achieve. The training algorithm involves the following steps:
- The actor network selects an action based on the current state.
- The agent takes the selected action in the environment and observes the resulting reward and next state.
- The critic network estimates the value of the selected action.
- The actor network is updated using the policy gradient, which is proportional to the advantage function. The advantage function measures the difference between the estimated value of the selected action and the estimated value of the best possible action.
- The critic network is updated using the temporal difference error, which is the difference between the estimated value of the selected action and the actual reward obtained.
Advantages of Actor-Critic Methods
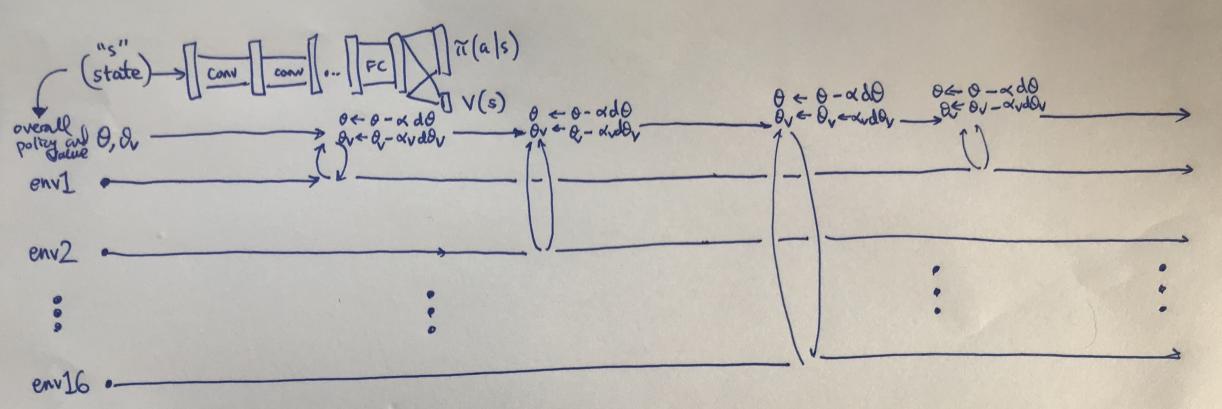
Actor-critic methods offer several advantages over other reinforcement learning algorithms:
- Sample Efficiency: Actor-critic methods are generally more sample-efficient than other reinforcement learning algorithms, meaning they require less data to learn optimal policies.
- Continuous Action Spaces: Actor-critic methods can be applied to problems with continuous action spaces, which are common in many real-world applications.
- Exploration: Actor-critic methods naturally encourage exploration, which is essential for learning optimal policies in large and complex environments.
Applications of Actor-Critic Methods
Actor-critic methods have been successfully applied to a wide range of problems, including:
- Robotics: Actor-critic methods have been used to train robots to perform complex tasks, such as walking, grasping objects, and navigating through cluttered environments.
- Game Playing: Actor-critic methods have been used to train agents to play games, such as chess, Go, and StarCraft, at a superhuman level.
- Natural Language Processing: Actor-critic methods have been used to train agents to perform natural language tasks, such as machine translation, text summarization, and question answering.

Actor-critic methods are a powerful class of reinforcement learning algorithms that have demonstrated impressive results in a variety of domains. Their ability to learn optimal policies in complex environments, their sample efficiency, and their applicability to continuous action spaces make them a valuable tool for researchers and practitioners alike.
YesNo

Leave a Reply