How Can I Implement Actor-Critic Methods in My Own Projects?
Actor-critic methods are a powerful class of reinforcement learning algorithms that have achieved great success in a wide range of applications, from robotics to game playing. They combine the strengths of actor networks, which learn to select actions, and critic networks, which evaluate actions and estimate state values. This combination allows actor-critic methods to learn optimal policies for complex tasks in a data-efficient manner.

Understanding The Components Of Actor-Critic Methods
Actor-critic methods consist of two main components:
Actor Network
- Selects actions based on the current state of the environment.
- Learns to improve its policy by maximizing the expected reward.
Critic Network
- Evaluates actions and estimates the value of states.
- Learns to provide accurate feedback to the actor network.
Implementing Actor-Critic Methods In Python
Actor-critic methods can be implemented in Python using popular libraries such as TensorFlow or PyTorch. Here's a step-by-step guide:
- Data Preprocessing: Prepare the data by normalizing inputs and converting labels to one-hot vectors.
- Model Architecture: Define the actor and critic networks. Common architectures include multilayer perceptrons (MLPs) and convolutional neural networks (CNNs).
- Loss Function: Define the loss function for training the actor and critic networks. Common loss functions include mean squared error (MSE) and cross-entropy.
- Optimizer: Choose an optimizer to minimize the loss function. Common optimizers include Adam and RMSProp.
- Training Procedure: Train the actor and critic networks by iteratively updating their weights based on the loss function.
Hyperparameter Tuning And Evaluation

Hyperparameter tuning is crucial for optimizing the performance of actor-critic methods. Common hyperparameters to tune include:
- Learning rate
- Batch size
- Network architecture
To evaluate the performance of actor-critic methods, metrics such as cumulative reward, success rate, and average episode length can be used.
Advanced Techniques And Considerations
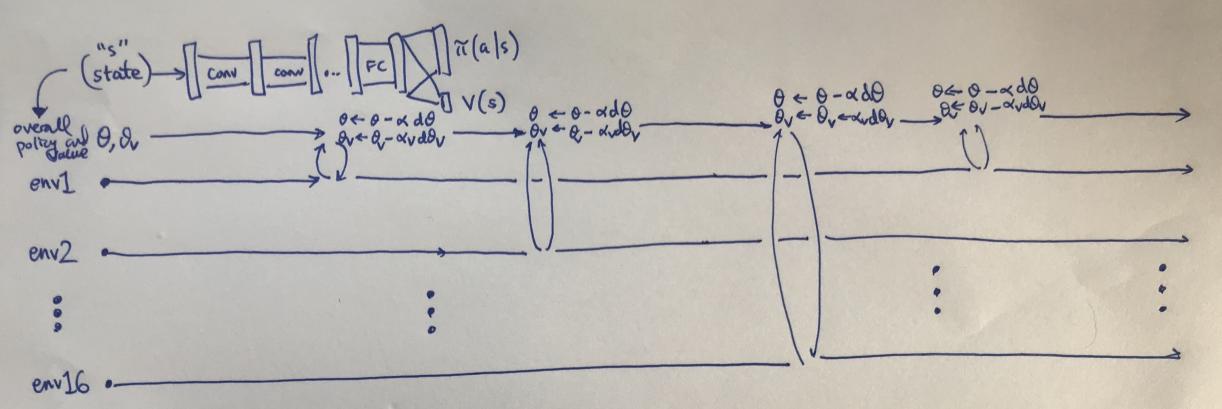
To enhance the performance of actor-critic methods, advanced techniques such as experience replay, target networks, and actor-critic with exploration can be employed.
When applying actor-critic methods to real-world applications, considerations such as handling large state spaces, continuous action spaces, and sparse rewards should be taken into account.
Actor-critic methods are powerful reinforcement learning algorithms with a wide range of applications. By implementing actor-critic methods in your own projects, you can leverage their strengths to solve complex tasks in a data-efficient manner.
Explore further resources and experiment with different applications of actor-critic methods to gain a deeper understanding of their capabilities.
YesNo

Leave a Reply